
Select a Llama (Pre-trained LLM) from the (Unsloth) Zoo
For this experiment we selected the ‘unsloth/Llama-3.2-3B-Instruct’ language model, a 3B parameter variant of Meta’s LLaMA 3 architecture. This model was optimised by the Unsloth project and is hosted (here) on the Unsloth zoo. We chose this particular model for its recency (2024) and performance on ubiquitous benchmarks, like HellaSwag (69.8), which demonstrated the model’s strong capability to balance performance and scale (Meta AI, 2024). Further, we incorporated the Unsloth version of the model, which provides built-in support for Low-Rank Adaptation (LoRA) to allow for parameter-efficient training by updating only a small fraction (0.81%) of model weights (Unsloth, 2024).
Our model choice was also motivated by the known compatibility with instruction-tuning, which closely aligns with the AG News classification task. Since we decided that the experiment’s objective would be to teach the model how to respond to prompts like “Classify this news: [text] Answer: [text]”, an instruct-tuned LLaMA variant was a logical fit. Finally, the use of Unsloth’s FastLanguageModel simplified integration with Hugging Face to pull datasets and enable stable training under 4-bit quantisation. This allowed the model to load efficiently into GPU memory with fewer precision errors.
# ---------------------------------------------
# 1. Install Required Packages
# ---------------------------------------------
%%capture
import os
if "COLAB_" not in "".join(os.environ.keys()):
!pip install unsloth
else:
# Do this only in Colab notebooks! Otherwise use pip install unsloth
!pip install --no-deps unsloth
!pip install --no-deps bitsandbytes accelerate xformers==0.0.29.post3 peft trl triton cut_cross_entropy unsloth_zoo
!pip install sentencepiece protobuf datasets huggingface_hub hf_transfer
# ---------------------------------------------
# 2. Import Required Libraries
# ---------------------------------------------
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, BitsAndBytesConfig
from unsloth import FastLanguageModel
from datasets import Dataset, load_dataset
from huggingface_hub import login
from unsloth import unsloth_train
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
from unsloth import UnslothTrainer, UnslothTrainingArguments
from huggingface_hub import login, HfApi, create_repo, Repository
# ---------------------------------------------
# 3a. Load Pre-trained Decoder-Only Language Model
# ---------------------------------------------
# https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.2_(1B_and_3B)-Conversational.ipynb#scrollTo=mCkIs33OhmZP
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
model_name = "unsloth/Llama-3.2-3B-Instruct"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = model_name,
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
device_map = {"": 0})
# ---------------------------------------------
# 3b. Add LoRA Adapters for Efficient Fine-Tuning
# ---------------------------------------------
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
use_rslora=False,
loftq_config=None,
)
Baseline Model Evaluation
The model was evaluated using both qualitative generation analysis and quantitative classification accuracy:
- Qualitative: Our bespoke qualitative measure required us to prompt the model with a short textual input (consistent with the theme of AGS News dataset) and inspect the generated continuation, allowing us to check the model’s semantic fluency, relevance, and alignment to the task (i.e., news genre classification based on short headlines/summaries). As part of our baseline assessment, we also extracted the top-k token continuation probabilities from the model’s final layer logits to understand its confidence distribution over vocabulary tokens.
- Quantitative: Our quantitative measure focused on classification accuracy over a subset of the AG News dataset. Prompts were generated in the format “Classify this news: [text] Answer: [text]”, and the generated output was matched against one of four label classes: World, Sports, Business, or Sci/Tech. Quantitative evaluation took place before and after fine-tuning using a (held-out) validation set.
Prompts used for evaluation followed the “instruction-tuning paradigm” (Zhang et al., 2024). Each input sample was phrased as: “Classify this news: [text] Answer: [text]”. The same format was used for both fine-tuning and evaluation. The model was evaluated using the AG News classification task, a standard multi-class text classification benchmark (Del Corso et al., 2005).
Let’s look at the example:
# ---------------------------------------------
# 4a. Baseline Qualitative Evaluation
# ---------------------------------------------
prompt = "Insurers are counting the cost of Hurricane Charley in Florida."
toks = tokenizer.encode(prompt)
print("Tokenised Prompt:", toks)
for t in toks:
print(f"{t}: {tokenizer.decode(t)}")
# Generate text continuation
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=30)
print("\nGenerated Text:")
print(tokenizer.decode(outputs[0]))
# Function to inspect continuation probabilities
def get_continuation_probability(prompt, model, tokenizer, top_k=5):
inputs = tokenizer(prompt, return_tensors='pt').to(model.device)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits[0, -1, :]
probs = torch.softmax(logits, dim=-1)
top_probs, top_indices = torch.topk(probs, top_k)
top_tokens = tokenizer.convert_ids_to_tokens(top_indices)
return list(zip(top_tokens, top_probs.tolist()))
# Example usage
print("\nTop-k continuation probabilities:")
continuation_probs = get_continuation_probability(prompt, model, tokenizer, top_k=5)
for token, prob in continuation_probs:
print(f"Token: {token}, Probability: {prob:.4f}")
# (Tokeniser used in Meta’s LLaMA-3 models: SentencePiece + BPE)
# Ċ -> /n
# Ġ-, Ġ( -> leading space
# ,, 's -> literal characters/punctuation
# ---------------------------------------------
# 4b. Baseline Quantitative Evaluation (i.e., before Fine Tuning)
# ---------------------------------------------
from sklearn.metrics import accuracy_score
label_names = ["World", "Sports", "Business", "Sci/Tech"]
label_map = {i: label for i, label in enumerate(label_names)}
# Prepare a small evaluation subset
baseline_eval_set = load_dataset("ag_news", split="train[1000:1050]")
correct = 0
samples = 0
for example in baseline_eval_set:
prompt = f"Classify this news: {example['text']} Answer:"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=30)
completion = tokenizer.decode(outputs[0], skip_special_tokens=True).lower()
predicted_label = None
for i, label in enumerate(label_names):
if label.lower() in completion:
predicted_label = i
break
if predicted_label == example['label']:
correct += 1
if samples < 25:
print(f"\nInput: {example['text'][:100]}...")
print(f"Expected Label: {label_names[example['label']]} | Completion: {completion.strip()}")
print(f"Predicted Label: {label_names[predicted_label] if predicted_label is not None else 'Unmatched'}")
samples += 1
baseline_accuracy = correct / samples
print(f"\n[Baseline Evaluation] Accuracy before fine-tuning on AG News [n={samples}]: {baseline_accuracy:.2%}")
# Expectation: Generates fluent text but not constrained labels.
# This is because it hasn’t been specifically trained to respond with:
# "World", "Sports", "Business", or "Sci/Tech"
# Thus, Predicted Label = Unmatched
Sample Outputs & Baseline Accuracy: 24.00%

Select a Fine-tuning Corpus
The model was fine-tuned using a 1,000-example subset of the AG News dataset from Hugging Face, which provides a realistic and diverse corpus of real-world news items. It is a well-known corpus consisting of English-language news headlines and brief summaries, each categorised into one of four balanced classes: “World”, “Sports”, “Business”, or “Sci/Tech”. It was created by the academic community (and intended for the academic community) in 2005 for research purposes in data mining, information retrieval, xml, data compression, data streaming, and other non-commercial activities.
Despite only having fine-tuned the model on a further (1,000 sample) AG subset, the Hugging Face dataset (here) and Papers with Code dataset (here) are AG News sub-datasets containing over 120,000 labelled news articles (30,00 training and 1,900 test samples per class). The dataset’s simplicity and even distribution of classes make it suitable for both fine-tuning and evaluation. For more information on the original data, please see here and here.
At tuning time, each data sample was transformed into an instruction-based prompt of the format previously described (“Classify this news: [text] Answer: [text]”). The formatting included a consistent prompt prefix (“Classify this news:”) and a fixed response prefix (“Answer:”) to match an instruction-tuning style expected by the unsloth/Llama-3.2-3B-Instruct model. Finally, an end-of-sequence (EOS) token was appended to ensure proper output truncation during generation. During formatting, care was taken to avoid repetition or label leakage by ensuring EOS consistency and prompt purity. This is because early on in development, we observed autoregressive leakage; i.e., what occurs when the target label appears in the input prompt, allowing a model to “cheat” by copying it, rather than learning to infer it. In this experiment, early prompt formats exposed the class label directly (e.g., embedding it in the text or response), causing the model to memorise patterns instead of generalising. This led to inflated accuracy during training (loss values only), but poor generalisation until the prompt was corrected to avoid leakage.
Fine-tuning was expected to improve both:
- Classification accuracy (quantitative measure), by aligning the model’s outputs more closely with the four AG News categories, and
- Response relevance and conciseness (qualitative measure), by anchoring generated text to valid class labels instead of drifting into general completion patterns.
We expected The instruct-tuned LLaMA model, initially trained on general-purpose dialogue data, struggled with classification alignment before task-specific tuning. Post-fine-tuning, it demonstrated strong generalisation to the test set and correctly responded to classification prompts.
# ---------------------------------------------
# 5. Fine-Tuning using UnslothTrainer
# ---------------------------------------------
from transformers import DataCollatorForSeq2Seq
dataset = load_dataset("ag_news", split="train[:1000]")
label_names = ["World", "Sports", "Business", "Sci/Tech"]
EOS_TOKEN = tokenizer.eos_token
def format_ag_news(example):
return {
"text": f"Classify this news: {example['text']}\nAnswer: {label_names[example['label']]}{EOS_TOKEN}"
}
dataset = dataset.map(format_ag_news)
print("Tokenizer type check:", type(tokenizer))
if not hasattr(tokenizer, 'pad'):
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=model_name,
max_seq_length=512,
dtype=None,
load_in_4bit=True,
device_map="auto"
)
trainer = UnslothTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = 512,
dataset_num_proc = 2,
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer),
args = UnslothTrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none",
),
)
print("\nFine-tuning the language model on AG News (UnslothTrainer)...")
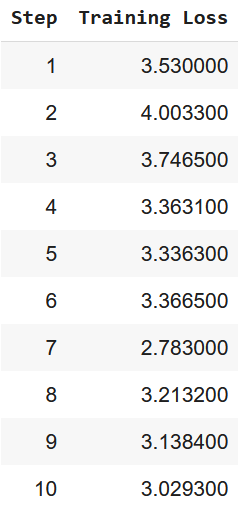
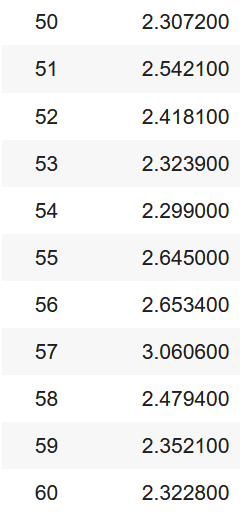
trainer.train()
…

Fine-tuned Model Evaluation
Our evaluation task remained consistent post-fine-tuning: AG News classification, a 4-class text classification problem from Hugging Face. The test split (first 100 examples) was held out for post-fine-tuning evaluation.
Before fine-tuning, the qualitative outputs were grammatically coherent but frequently misaligned with the task objective. The model tended to generate irrelevant or verbose completions, and early stages of development exhibited autoregressive leakage (e.g., repeating prompt patterns like “Answer: Answer: Answer:”). Additionally, the top-k continuation probabilities often included generic or template-based tokens (e.g., “The”, “Here”), indicating limited task conditioning.
In contrast, post-fine-tuning outputs were more concise and task-aligned. The model learned to produce accurate labels and terminate appropriately. After fine-tuning, the token probabilities aligned more closely with domain-specific outputs (e.g., “World”, “Business”, “Sci/Tech”), meaning that completions were consistent with the four-class labelling scheme from the AG News corpus. Our quantitative evaluation also reflected this: before fine-tuning, the baseline accuracy was 24.00% (i.e., close to chance-level for 4 classes), whereas fine-tuning on just 1,000 examples increased our test accuracy to 87.00% on a (held-out) AG News test subset.
# ---------------------------------------------
# 6. Qualitative Evaluation (After Fine-Tuning)
# ---------------------------------------------
prompt = "Classify this news: The prime minister met with cabinet officials to discuss changes in economic policy.\nAnswer:"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=3,
repetition_penalty=1.5,
do_sample=False,
eos_token_id=tokenizer.eos_token_id
)
print("\nGenerated Answer:")
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
## (Previously) Autoregressive leakage:
# Generated Answer:
# Classify this news: The prime minister met with cabinet officials to discuss changes in economic policy.
# Label: Label: Label: Label
# ---------------------------------------------
# 7. Quantitative Evaluation (After Fine-Tuning)
# ---------------------------------------------
print("\n[Post-Fine-Tuning Evaluation] Logging model predictions:")
post_eval_set = load_dataset("ag_news", split="test[:100]")
correct = 0
samples = 0
for example in post_eval_set:
prompt = f"Classify this news: {example['text']}\nAnswer:"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=3,
repetition_penalty=1.5,
do_sample=False,
eos_token_id=tokenizer.eos_token_id
)
completion = tokenizer.decode(outputs[0], skip_special_tokens=True).lower()
predicted_label = None
for i, label in enumerate(label_names):
if label.lower() in completion:
predicted_label = i
break
if predicted_label == example['label']:
correct += 1
if samples < 25:
print(f"\nInput: {example['text'][:100]}...")
print(f"Expected Label: {label_names[example['label']]} | Completion: {completion.strip()}")
print(f"Predicted Label: {label_names[predicted_label] if predicted_label is not None else 'Unmatched'}")
samples += 1
final_accuracy = correct / samples
print(f"\n[Post-Fine-Tuning Evaluation] Accuracy on AG News test set [n={samples}]: {final_accuracy:.2%}")

Conclusions
Post-fine-tuning results aligned with our expectations for this experiment’s task-specific training. Our training loss decreased from an initial 3.53 to 2.68 over 60 steps after one (LoRA) epoch.
Additionally, as previously stated, classification accuracy increased from 24.00% to 87.00% and our (qualitative) completions were significantly more task-specific. The model also stopped hallucinating verbose completions and repeating prompt fragments (i.e., experiencing leakage).
Most importantly, the generated labels mapped clearly to the AG News taxonomy, indicating successful conditioning. That is, our AG News subset was sufficient to condition the model towards the task-aligned behaviour. Despite the relatively small sample size used for tuning (1,000 instances), the model adapted well to its task. Notably, it also did so fairly efficiently (‘train_runtime’: 131.8039).
Thus, our results support the efficacy of the instruction-tuning paradigm, as well as usefulness of LoRA-based fine-tuning and strong generalisability of the pretrained base.
References
Del Corso, G. M., Gulli, A., & Romani, F. (2005). Ranking a Stream of News. Proceedings of the 14th International World Wide Web Conference (WWW 2005), 97–106. http://groups.di.unipi.it/~gulli/AG_corpus_of_news_articles.html
Meta AI. (2024). Llama 3.2: Revolutionizing edge AI and vision with open, customizable models. In Meta. https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
Unsloth. (2024). Llama 3.2 (1B and 3B) Conversational. In Unsloth.Zhang, S., Dong, L., Li, X., Zhang, S., Sun, X., Wang, S., Li, J., Hu, R., Zhang, T., Wu, F., & Wang, G. (2024). Instruction Tuning for Large Language Models: A Survey. https://arxiv.org/abs/2308.10792
